Rasqal 0.9.21 was just released on Saturday 2010-12-04 (announcement) containing the following new features:
- Updated to handle aggregate expression execution as defined by the SPARQL 1.1 Query W3C working draft of 14 October 2010
- Executes grouping of results:
GROUP BY - Executes aggregate expressions:
AVG,COUNT,GROUP_CONCAT,MAX,MIN,SAMPLE,SUM - Executes filtering of aggregate expressions:
HAVING - Parses new syntax:
BINDINGS,isNUMERIC(),MINUS, subSELECTandSERVICE. - The syntax format for parsing data graphs at URIs can be explictly declared.
- The
roqetutility can execute queries over SPARQL HTTP Protocol and operate over data from stdin. - Added several new APIs
- Fixed Issue: #0000388
See the Rasqal 0.9.21 Release Notes for the full details of the changes.
I'd like to emphasis a couple of the changes to the roqet(1) utility
program: you can now use it to query over data from standard input, i.e.
use it as a filter, but only if you are querying over one graph. You can
also specify the format of the data graphs either on standard input or
from URIs, if the format can't be determined or guessed from the mime
type, name or bytes. Finally roqet(1) can execute remote queries at a
SPARQL Protocol HTTP service, sometimes called a "SPARQL endpoint".
The new support for SPARQL Query 1.1 aggregate queries (and other features) led me to make comments to the SPARQL working group about the latest SPARQL Query 1.1 working draft based on the implementation experience. The comments (below) were based on the implementation I previously outlined in Writing an RDF query engine. Twice at the end of October 2010.
The implementation work to create the new features was substantial but relatively simple to describe: new rowsources were added for each of the aggregation operations and then included in the execution plan when the query structure indicated their presence after parsing. There was some additional glue code that needed to be add to allow rows to indicate their presence in a group; a simple integer group ID was sufficient and the ID value has no semantics, just a check for a change of ID is enough to know a group started or ended.
I also introduced an internal variable to bind the result of
SELECT aggregate expressions after grouping ($$aggID$$
which are illegal names in sparql). I then used that to replace the
aggregate expression in the SELECT and the HAVING expressions and
used the normal evaluation mechanisms. As I understand it, the
SPARQL WG is now considering adding a way to name these explicitly
in the GROUP statement. A happy coincidence since I had implemented
it without knowing that.
To prepare this I did think about the approach a lot and developed a couple of diagrams for the grouping and aggregation rowsources that might help to understand how they work, how they can be implemented and tested as standalone unit modules, which they were.

As always, the above isn't quite how it is implemented. There is no
group by node if there is an implicit group when GROUP BY is missing
but an aggregate expression is used; instead the Rasqal rowsource class
synthesizes 1 group around the incoming row, when grouping is requested.

This shows the guts of the aggregate expression evaluation where
internal variables are introduced, substituted into the SELECT and
HAVING expressions and then created as the aggregate expressions are
executed over the groups.
The rest of this post are my detailed thoughts on this draft of SPARQL 1.1 Query as posted to the SPARQL WG comments list but turned into HTML markup here.
** Dave Beckett comments on SPARQL 1.1 Query Language W3C WD 2010-10-14 **
These are my personal comments (not speaking for any past or current employer) on: SPARQL 1.1 Query Language W3C Working Draft 14 October 2010
My comments are based on the work I did to add some SPARQL 1.1 query and update support to my Rasqal RDF query library (engine and API) in version 0.9.21 just released 2010-12-04 as
Some background to my work is given in a blog post: Writing an RDF query engine. Twice
I. General comments
I felt the specification introduced more optional features bundled
together, where it was not entirely clear what the combination of
those features would do. For example a query with no aggregate
expression but has a GROUP BY and HAVING is
allowed by the syntax and the main document doesn't say if it's
allowed or what it means.
I found it hard to assemble all the pieces from the mathematical explanations into something I could code.
The spec has several terms in the grammar not in the query
document. After asking, these turned out to be federated query
(BINDINGS), or update (LOAD, ...) but these are not
pointed out or linked to clearly although there is mention of the
documents in the status section. Please make these more clear.
I decided to concentrate on the new Aggregates feature since I had
already implemented SELECT expressions, leaving
Subqueries and Negation to later. Property
paths should be in the list of new features in the status
section at the of the document.
"SPARQL 1.1 Uniform HTTP Protocol for Managing RDF Graphs" is rather a long title; what does 'Uniform' or 'HTTP' add? SOAP is dead. suggest "SPARQL 1.1 RDF Graph Management Protocol" or RDF dataset
With all the additions especially property paths (a new query language), update (data management language) and federated query (remote query support) and I understand \~30 additional keywords are being added beyond this draft for functions and operators, I see this as a major change to SPARQL 1.0, more of a SPARQL 2. You should consider renaming it.
II. Aggregates
I found the math in the aggregation and grouping sections rather hard to understand so I also looked what MySQL and SQLite did, and wrote my own diagram based on the data flow:
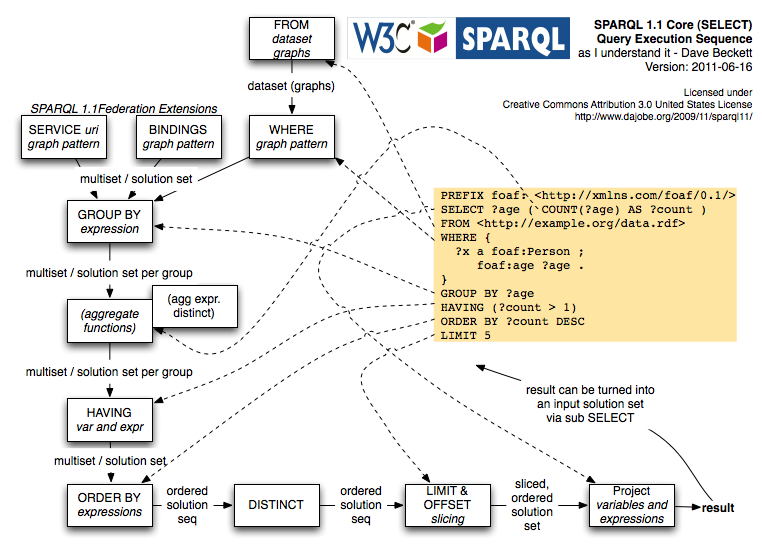
See SPARQL 1.1 Query Execution Sequence
so for me it was easier to see the individual components/stages (which roughly correspond to SPARQL algebra terms).
I had to make several of my own tests with my guess on what the answers should be. With all the pieces for aggregate expressions: grouping, aggregate expression, distinct, having, counting (count * vs count(expr)) there needs to be several tests with good coverage.
I felt aggregate functions can be broken down into these parts
- selecting of aggregate function value
- grouping of results - optional; explicit, implicit when agg func present
- execution of aggregate functions - optional; with some special cases
- filtering of group results with having - optional
(following my diagram above)
As it is clear they are all optional, it probably is worth explaining what it means when they are absent, such as group by + having with no aggregate expression as mentioned above.
III. Bindings is a new syntax
BINDINGS essentially gives a new way to write down a variable
bindings result set. Even though it is discussed in the federated
query spec about using it for SERVICE, it's not restricted to that
by
the grammar or specifications.
BINDINGS in the query grammar
(rBindingsClause)
I previously asked about
on
2010-10-15
and this comment is an extension of that comment.
So as I read it this is a valid 'query' which does no real execution but just returns a set.
SELECT * WHERE BINDINGS ?var1 ?var2 {
( "var1-value1" "var2-value1" )
( "var1-value2" "var2-value2" )
}
or if you really must you can leave out the WHERE:
SELECT * BINDINGS {
( "var1-value1" "var2-value1" )
( "var1-value2" "var2-value2" )
}
My question is to ask if this is correct and to clarify in the
spec the intended use, whether or not it is intended for use with
SERVICE only.
IV. Section-by-section comments
Section: Status of this Document
Should mention property paths as new since that is a major addition after SPARQL 1.0
Please link to the documents in the status, these are just text.
Sections 1-8
Skipped, they are same as SPARQL 1.0 I hope
9 Property Paths
I am unlikely to ever implement any of this, it's a second query language inside SPARQL. How many systems implemented this before the SPARQL 1.1 work was started?
10 Aggregates
I took all the examples in this section and turned them into test cases where possible.
10.2
The explanation of errors and ListEvalE is rather opaque. It is still not clear to me what is done with errors in GROUP BY, HAVING and arguments to aggregate expressions. Some are skipped, some are ignored and return NULL. Examples and tests will enable checking this but the spec needs to be clearer.
Definition: Group and Aggregation were hard for me to understand. The input to Aggregation being a 'scalar' meaning actually a set of key:value pairs was confusing. It is not also not clear if those are a set or an ordered set of parameters. This is only used today for the 'separator' with GROUP_CONCAT.
10.2.1 HAVING
What happens when there is an expression error?
What variables and expressions can be used here and what is their scope?
10.2.2 Set Functions
Another confusing section. I mostly ignored this and did what SQL did.
None of the functions that I can tell, ever use 'err'.
10.2.3 Mapping from Abstract Syntax to Algebra
scalarvals argument is used here - I think this is called 'scalar' earlier.
Un-numbered Section after 10.2.3: Joining Aggregate Values
Never figured out what this was trying to define but my code executes the example.
11. Subqueries
(Ignored in my current work)
12 RDF Dataset
(Same as SPARQL 1.0 I assume so no comments)
13 Basic Federated Query
Yes, please merge in the text here.
14 Solution Sequences and Modifiers
( Aside: This is one of those SPARQL parts where everything mentioned is optional. Otherwise this section has no change from SPARQL 1.0, I am just mentioning it as a pointer of a trend. )
15. Query Forms
No comments.
16. Testing Values
16.3 Operator Mapping
Is it worth noting the new operators in SPARQL 1.1?
Operators: implemented isNUMERIC()
16.4 Operators Definitions
My current state of implementation of new to SPARQL 1.1 expressions
- 16.4.16 IF - implemented
- 16.4.17 IN - implemented
- 16.4.18 NOT IN - implemented
- 16.4.19 IRI - implemented
- 16.4.20 URI - implemented
- 16.4.21 BNODE - implemented
- 16.4.22 STRDT - implemented
- 16.4.23 STRLANG - implemented
No comments on the above
16.4.24 NOT EXISTS and EXISTS
I am lumping these together with sub-SELECT to implement.
My concern here is that the syntax gets super-complex since all the
graph
pattern syntax can now appear inside any expression syntax.
There is a filter operator "exists" that ...
Does this imply these can only appear in FILTER
expressions? Please clarify.
17 Definition of SPARQL
I looked at the 17.2.3 for aggregate queries and it was more helpful than the math earlier. The pseudo code in Step 4 is a bit too unclear. Is that an example implementation or the required one?
17.6 Extending SPARQL Basic Graph Matching
Ignored.
18 SPARQL Grammar
Clearly this is not complete; there are lots of notes to update it.
19 Conformance
If property paths are not removed, please add a conformance level that includes SPARQL 1.1 without property paths.
Does SPARQL 1.1 Query require implementation of the dependent specs - federated query and update? Looks to me that protocol may also be dependent?