"You'll end up writing a database" said Dan Brickley prophetically in
early 2000. He was of course, correct. What started as an RDF/XML parser
and a BerkeleyDB-based triple store and API, ended up as a much more
complex system that I named Redland with the
librdf API. It does indeed have persistence, transactions (when using
a relational database) and querying. However, RDF query is not quite the
same thing as SQL since the data model is schemaless and graph centric
so when RDQL and later SPARQL came along, Redland gained a query engine
component in 2003 named Rasqal: the RDF
Syntax and Query Library for Redland. I still consider it
not a 1.0 library after over 7 years of work.
Query Engine The First
The first query engine was written to execute
RDQL which today looks like a
relatively simple query language. There is one type of SELECT query
returning sequences of sets of variable bindings in a tabular result
like SQL. The query is a fixed pattern and doesn't allow any optional,
union or conditional pattern matching. This was relatively easy to
implement in what I've called a static execution model:
- Break the query up into a sequence of triple patterns: triples that can include variables in any position which will be found by matching against triples. A triple pattern returns a sequence of sets of variable bindings.
- Match each of the triple patterns in order, top to bottom, to bind the variables.
- If there is a query condition like
?var > 10then check that it evaluates true. - Return the result.
- Repeat at step #2.
The only state that needed saving was where in the sequence of triple patterns that the execution had got to - pretty much an integer, so that the looping could continue. When a particular triple pattern was exhausted it was reset, the previous one incremented and the execution continued.
This worked well and executes all of RDQL no problem. In particular it was a lazy execution model - it only did work when the application asked for an additional result. However, in 2004 RDF query standardisation started and the language grew.
Enter The Sparkle
The new standard RDF query language which was named SPARQL had many
additions to the static patterns of the RDQL model, in particular it
added OPTIONAL which allowed optionally (sic) matching an inner set of
triple patterns (a graph pattern) and binding more variables. This is
useful in querying heterogeneous data when there are sometimes useful
bits of data that can be returned but not every graph has it.
This meant that the engine had to be able to match multiple graph patterns - the outer one and any inner optional graph pattern - as well as be able to reset execution of graph patterns, when optionals were retried. Optionals could also be nested to an arbitrary depth.
This combination meant that the state that had to be preserved for getting the next result became a lot more complex than an integer. Query engine #1 was updated to handle 1 level of nesting and a combination of outer fixed graph pattern plus one optional graph pattern. This mostly worked but it was clear that having the entire query have a fixed state model was not going to work when the query was getting more complex and dynamic. So query engine #1 could not handle the full SPARQL Optional model and would never implement Union which required more state tracking.
This meant that Query Engine #1 (QE1) needed replacing.
Query Engine The Second
The first step was a lot of refactoring. In QE1 there was a lot of shared state that needed pulling apart: the query itself (graph patterns, conditions, the result of the parse tree), the engine that executed it and the query result (sequence of rows of variable bindings). That needed pulling apart so that the query engine could be changed independent of the query or results.
Rasqal 0.9.15 at the end of 2007 was the first release with the start of the refactoring. During the work for that release it also became clear that an API and ABI break was necessary as well to introduce a Rasqal world object, to enable proper resource tracking - a lesson hard learnt. This was introduced in 0.9.16.
There were plenty of other changes to Rasqal going on outside the query engine model such as supporting reading and writing result formats, providing result ordering and distincting, completing the value expression and datatype handling data and general resilience fixes.
The goals of the refactoring were to produce a new query engine that was able to execute a more dynamic query, be broken into understandable components even for complex queries, be testable in small pieces and to continue to execute all the queries that QE1 could do. It should also continue to be a lazy-evaluation model where the user could request a single result and the engine should do the minimum work in order to return it.
Row Sources and SPARQL
The new query engine was designed around a new concept: a row source.
This is an active object that on request, would return a row of variable
bindings. It generates what corresponds to a row in a SQL result. This
active object is the key for implementing the lazy evaluation. At the
top level of the query execution, there would be basically one call to
top_row_source.getRow() which itself calls inner rowsources'
getRow() in order to execute the query to return the next result.
Each rowsource would correspond approximately to a SPARQL algebra concept, and since the algebra had a well defined way to turn a query structure into an executable structure, or query plan, the query engine's main role in preparation of the query was to become a SPARQL query algebra implementation. The algebra concepts were added to Rasqal enabling turning the hierarchical graph pattern structure into algebra concepts and performing the optimization and algebra transformations in the specification. These transformations were tested and validated against the examples in the specification. The resulting tree of "top down" algebra structures were then used to build the "bottom up" rowsource tree.
The rowsource concept also allowed breaking up the complete query engine execution into understandable and testable chunks. The rowsources implemented at this time include:
- Assignment: allowing binding of a new variable from an input rowsource
- Distinct: apply distinctness to an input rowsource
- Empty: returns no rows; used in legitimate queries as well as in transformations
- Filter: evaluates an expression for each row in an input rowsource and passes on those that return True.
- Graph: matches against a graph URI and/or bind a graph variable
- Join: (left-)joins two inner rowsources, used for OPTIONAL.
- Project: projects a subset of input row variables to output row
- Row Sequence: generates a rowsource from a static set of rows
- Sort: sort an input rowsource by a list of order expressions
- Triples: match a triple pattern against a graph and generate a row. This is the fundamental triple pattern or Basic Graph Pattern (BGP) in SPARQL terms.
- Union: return results from the two input rowsources, in order
The QE1 entry point was refactored to look like getRow() and the query engines were tested against each other. In the end QE2 was identical, and eventually QE2 was improved such that it passed more DAWG SPARQL tests that than QE1.
So in summary QE2 works like this:
- Parse the query string into a hierarchy of graph patterns such as
basic, optional, graph, group, union, filter etc. (This is done in
rasqal_query_prepare()) - Create a SPARQL algebra expression from the graph pattern tree that
describes how to evaluate the query. (This is in
rasqal_query_execute()calling QE2 ) - Invert the algebra expression to a hierarchy of rowsources where the top rowsource getRow() call will evaluate the entire query (Ditto)
(If you want to see some of the internals on a real query, run
roqet -d debug query.rq from roqet built in maintainer mode and both
the query structure and algebra version will be generated.
The big advantage from a maintenance point of view is that it is divided into small understandable components that can be easily added to.
The result was released in Rasqal 0.9.17 at the end of 2009; 15 months
after the previous release. It's tempting to say nobody noticed the new
query engine except that it did more work. There is no way to use the
old query engine except by a configure argument when building it. The
QE1 code is never called and should be removed from the sources.
Example execution
When QE2 is called by the command line utility roqet, there is a lot going on inside Rasqal and Raptor. A simplified version of what goes on when a query like this is run:
$ cat example.rq
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?name ?website
FROM <http://planetrdf.com/bloggers.rdf>
WHERE { ?person foaf:weblog ?website ;
foaf:name ?name .
?website a foaf:Document
}
ORDER BY ?name
$ roqet example.rq
roqet: Querying from file example.rq
roqet: Query has a variable bindings result
result: [name=string("AKSW Group - University of Leipzig"), website=uri<http://blog.aksw.org/>]
...
is described in the following picture if you follow the numbers in order:
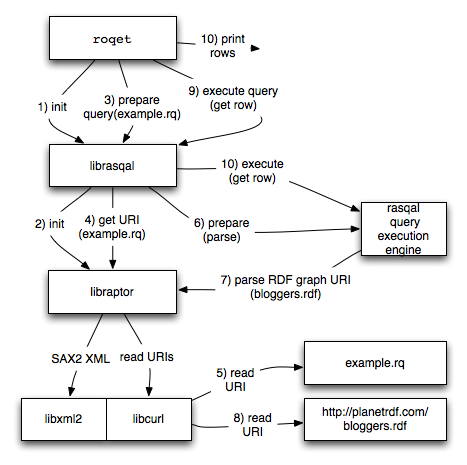
This doesn't include details of content negotiation, base URIs, result formatting, or the internals of the query execution described above.
SPARQL 1.1
Now it is the end of 2010 and SPARQL 1.1 work is underway to update the original SPARQL Query which was complete in January 2008. It is a substantial new version that adds greatly to the language. In the SPARQL 1.1 2010-10-14 draft version it adds (these items may or may not be in the final version):
- Assignment with
BIND(expr AS ?var) - Aggregate expressions such as
SUM(),COUNT()including grouping and group filtering withHAVING - Negation between graph patterns using
MINUS. - Property path triple matching.
- Computed select expressions:
SELECT ... (expr AS ?var) - Federated queries using
SERVICEto make SPARQL HTTP query requests - Sub
SELECTandBINDINGSto allow queries/results inside queries. - Updates allowing insertion, deletion and modification of graphs via queries as well as other graph and dataset management
The above is my reading of the major items in the latest draft SPARQL 1.1 query language or it's dependent required specifications.
Rasqal next steps
So does SPARQL 1.1 mean Rasqal Query Engine 3? Not yet, although the Rasqal API is still changing too much to call it stable and another API/ABI break is possible. There's also the question of making an optimizing query engine, a more substantial activity. At this time, I'm not motivated to implement property paths since it seems like a lot of work and there are other pieces I want to do first. Rasqal in GIT handles most of the syntax and is working towards implementing most of the execution of aggregate expressions, sub selects and SERVICE although no dates yet. I work on Rasqal in my spare time when I feel like it, so maybe it won't be mature with a stable API (which would be a 1.0) until SPARQL 2 rolls by.