Dave Beckett
Yahoo! Inc
701 1st Avenue, Sunnyvale, CA 94089, USA
This paper discusses tags, tagging and how these are used on the popular web sites now, along with a suggested process on how to go from a Tag to the Semantics that a human can understand. The paper will discuss how a combination of existing services, technology and processes can provide a possible solution along with problems that this has.
First I'll attempt to define the core terms:
Tagging
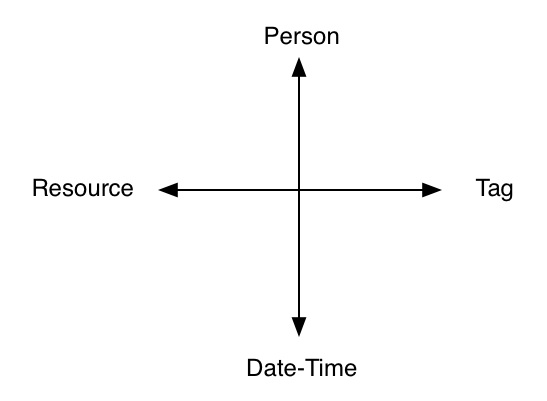
A lightweight process to describe web content using items called Tags. The tagging process is primarily a combination of 4 entities:
The person performing the operation (the tagger)
The web resource URI that is being described.
The date and time the tagging is performed .
The set of tags of tags used (tagset)
as shown in Figure 1.
tag-4ary-predicate.jpg
Figure 1. The tagging process takes a Resource, Person, Tag and Date-Time
Tag
A word or short phrase which has a meaning to a person, not taken from any pre-designed system. Multiple tags are called a tagset since the order of tags is usually not important and means all the tags are relevant (an AND).
Or trying to get it in one phrase:
Tagging: describing web content using whatever words seem right
which is probably as simple as it can be defined.
Tagging is most commonly used for bookmarking web sites, annotating photos and annotating items posted on a personal weblog. Each individual tag (and sometimes tagsets) is considered an important entity and is usually given it's own associated URIs where the web sites providing the tagging and tags present some appropriate content related to the tag such as:
listing all resources known by the service with that tag
a syndication feed of the lists in Atom[NOT05] or RSS[PIL04]
additional information such as related tags to the one in hand.
If a tagging system has the notion of users, that is also presented although the user information itself is outside of the tag, and is really part of the process of tagging. Systems may give URIs for the taggings-per-user for example in deli.cio.us and Flickr, but not all. Also outside the tag is the point in time at which the tagging was performed, although that may be available if there is a syndication feed of the taggings for some tag, which has a date field.
Many others have defined tags and tagging including:
“Tags are simply labels for URLs, selected to help the user in later retrieval of those URLs.”, [SHI05]
but that only applies to where the URI is primary the information of interest rather than (say) your photos, so this definition mainly applies to URI bookmarking sites such as del.icio.us, as discussed below.
“tagging is on-the-fly user generated keyword
categorization”
[GAL05]
which seems over-specific and seems to imply that there is a construction of a hierarchical categorization, which is not required.
[tagging is] “marking content with descriptive terms, called keywords or tags” [GOL06]
“Tags are keywords, category names, or metadata” [GUY05]
but they are not always such as the infamous “toread”.
“The
job of tags isn't to organize all the world's information into tidy
categories,” said Stewart Butterfield, one of Flickr's
co-founders. “It's to add value to the giant
piles of data that are already out
there.”
[TER05]
This quote seems to be the most useful as guiding the purpose that tags evoke — a practical description technology, with a social purpose both for the person and for the group. However it is not entirely clear if people are using the term in the same way.
There is no structure in tag names or in the use of multiple tags in co-operation. Despite that, structure and hieararchy of tagging has emerged primarily by how it was used but sometimes by design. This section describes the more widely-seen tagging practices.
A tag cloud is a multiset of tags where each tag can appear with a count higher than 1. This is most commonly seen on pages which use the font size/boldness to emphasise the cardinality of the tag. This is a common default view of the top level of a tag URIspace (Flickr, del.icio.us, Technorati) but it is also shown for groups and individuals such as tags used on postings on a weblog. Figure 2 shows the tag cloud for del.icio.us at the time of writing.
Figure 2. Tag cloud of popular tags on del.icio.us at http://del.icio.us/tag/
Tags can be used to record the location of the tagged item in the real world which is known under the general name of Geotagging. This is most often seen on Flickr as there is a high motivation to record where a picture was taken in order to find it again, or for sharing.
The main geotags are for recording latitude and longitude with decimal values in two tags like: geo:lat=123.456 geo:long=-123.45which are of little use outside the pair. This is breaking down an opaque tag name into key/value pairs and then combining both to give an interpretation — a location on the planet.
US-specific geotagging can be done with the US Postal Codes, called Zip Codes like zip:12345which have standard mappings to geographical spaces, again a key/value pair.
Mobile cell phone information used when a picture was taken on a cameraphone are recorded using Celltagging which involves multiple fields and values. The tags used are typically like:
celltagged
cell:network=MyNetwork
cell:mcc=300
cell:mnc=400
cell:lac=5000
cell:cellid=6000
This is much more than tags for simple word-style categorizing of web content, it is a small data structure.
Phones that have Bluetooth capability can discover which phones (and hence people) that are nearby, which is one way to read the social network in the context of a photo and which can be recorded in the tagging. This is called Bluetagging and uses a tag that forms the Bluetooth device IDs like Bt=001234abcdefwhich are repeated for each Bluetooth device in range.
It is not enough for people to just tag resources with the buckets that they go into, since there are natural as well as formal categories and sub-categories in many uses of description, from locations (Country, County, City, ”¦) to subject topics. This has emerged on del.ico.us by the use of hieararchical tags using ”˜/' to separate parts of the hierarchy, like in URIs.
Google Mail allows the use of short word markers for emails which are presented as folders and are searchable. These are not tags mostly because they are not shared, there is no tagging date context and the primary entities they describe (emails) have no single URI in this user interface.
Keywords are not tags, especially when thought of in an academic context, keywords used to describe a paper are usually taken from a pre-selected allowed list and are more like short phrases than a tagset.
“Tags
are one-word descriptors that you can assign to any
bookmark.”
What are tags, http://del.icio.us/help/tags
“there is no such thing as a right or wrong tag. A tag is
whatever you want it to be.”
http://del.icio.us/help/posttags
del.icio.us is a social bookmarks web site, so the focus on tagging is with respect to annotating a bookmark URI. The default and only required field is one labeled description. Tags are very much encouraged in the bookmarking process, including presenting suggested tags on the post form once a URI is given as shown in Figure 3.
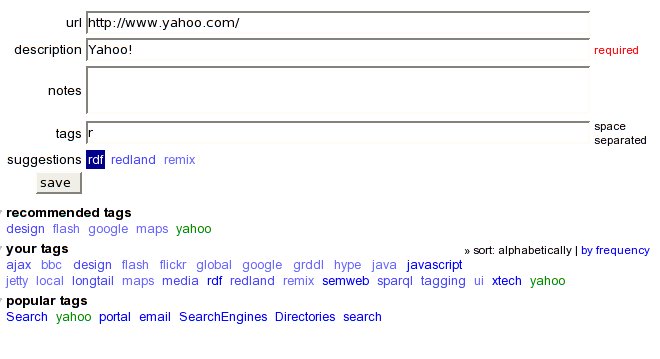
Figure 3. Tag suggestions while posting a bookmark on del.icio.us
The emphasis on the home page is a tag-centric view of bookmarks which are seen as folders. There are multiple ways to look at the contents of folders and to navigate the folderspace.
All content tagged on deli.cio.us are URIs so tagging here is mostly content that is not owned by the person doing the tagging — although there is nothing preventing annotating URIs that are on the del.icio.us site itself. The social aspects focus on popularity, the URI and the tag, but with no discussion possible apart what is written in the description field.
Some novel uses of tags seen on del.icio.us are for:personwhich triggers a site mechanism to send tags to other users on the site. It also provides bundles (http://del.icio.us/help/bundles) to group tags allowing the forming of a hierarchy. Users are also experimenting themselves with hierarchies by using tags like Programming/Java to indicate more than just ProgrammingAND Java which is all you get with a tagset.
What are
tags?
#37 Tags are like keywords or labels that you can add
to a photo to make it easier to find later.
http://www.flickr.com/help/tags/
The focus of Flickr is photographs and the primary description is to give photos titles and descriptions although parts of an image may be annotated with additional descriptions. Tagging remains optional but is encouraged, although it does not presently offer suggestions. On the Flickr site you can tag any image present and there are rich interfaces such as tag clouds, group tags and clusters to provide multiple ways to browse photos via tags. There are many groups that use the structured tagging approaches described above but there is at present no special support for these in the user interface.
Tags are simply
free-form keywords people have used to describe their
posts.
Popular tags on Metafilter, http://www.metafilter.com/tags/
Which is a classic bookmarking approach to tags similar to delicious. There are no special views of tags here.
Technorati Tags are used inside HTML content as syndicated via feeds. The technorait aggregator looks for the rel=”tagâ€attribute on links and uses that to mark URIs that are relevant to a tag — the tagging context. The syndication feed records the remainder of the tagging information — who tagged it (weblog author) and when (feed entry date). The Technorati tags are primarily for aggregation — there is no community to join, although you do have to register the syndication feed to appear.
Question: Is a tag on deli.cio.us the
same tag as one on Technorati or on Flickr?
Answer: Does anyone care?
Tags can have URIs when they are associated with well known services, however the tags themselves are the short names flowerrather than the URI that some service uses to browse them such as http://www.flickr.com/photos/tags/flower/ .
So if it makes sense to join data using the tag itself, services like Technorati provide that by linking to the Flickr tag URIs for the same tags they find in web pages. The actual overlap between the large tagging services is however, rather small except around current events, major locations, dates and for some technical topics.
These services do use tagging rather differently so these spaces when they are considered on their own are their own separate worlds of tags, which could be called tagonomies as they are tag-based social spaces.
Semantics for tagging are needed for two main purposes:
For people to understand what some use of a tag means.
For computers to gather information about a tag, supporting purpose #1
What does a tag mean to a person? The obvious answer to this is to ask them, but this is not a network-scalable answer and you may not even be able to contact the person. Another choice would be to look it up in a dictionary for some language (assuming you know which one), but that provides a baked semantics that may not be what was intended; one key aspect of tagging is that the words can evolve fast, and then you will not be able to find where they are defined.
The semantics of a tag is primarily about what it means to some person or group of people, although this can be aided by machine description, the machine description is not the main goal.
Additional tags nearby the tag in question can also aid in discovering the meaning and aiding disambiguation such as used in clustering around one tag used for different purposes such as used in Flickr Clustering and Interestingness[BUT05]
These issues still leave the meaning open as to some fuzzy emergent answer without any good community or social context around it. This is where the social networking part of tagging stops.
The remainder of this paper considers approaches to finding semantics for tags used for the purposes given above.
Tags as they exist now have multiple good points in their favour:
There is a very low barrier to starting to use them; just begin typing
There are few restrictions on how they are used (just syntax) although some like del.icio.us do provide suggested tags.
You escape from barriers and restrictions of pre-created closed lists of allowed terms, such as index catalogues used in the library world.
You participate in a collaborative description effort, a folksonomy.
As the number of tags increase, the description gets better and individuals have less of an effect (although this can be seen as a downside).
Easy to experiment with new ideas for description and structuring.
However there are lots of what might be called formalism problems with tagging that are identified by people familiar with classical classification systems such as mixing types of things, names of things, genres, made up things, ambiguity, synonyms and such. As an example, the 'toread' tag — in the most popular tags list of del.icio.us is notpeople describing the content, it's part of a person's context, their own taxonomy. Interpreting this globally is going to be of little use apart from finding a list of the most planned-to-read items, or maybe you could call it, the under-read.
These formalism problems are mostly known and thought not worth worrying about in the tagging community as the ease using of tags with few restrictions greatly beats the usability of more complex formalism systems with complex restrictions. However, this trade-off means that there is no easy route for non-experts to use tagging to address these problems, as there are no more mechanisms built into the concept apart from the tag words; you can't say a tag is “AmbiguousWord meaning #5”.
"in folksonomies there are no such things as synonyms, because users employ tags for specific reasons" [SHI05]
However you can't tell what these reasons are.
The deliberate low barrier for using tags has the consequence that the meaning of a tag has to be implicit as there is no easy way to find out some tag means by a directory or catalog. The words are mostly written in some human language but which one is not usually recorded, so tagging also loses in the internationalization stakes, unless that is somehow attached to the person, however this is not sufficient as people can use multiple languages at the same time.
The aggregation of many tags creates one of the oft-repeated “power curves” that has a long-tail where some resources or tags are not described or used much. Although the well-used tags will gain tend over time to tend towards an emergent common meaning, this does not help when a tag has fewer uses.
Tagging has the usual human entered metadata problem, the data can be poor if it is not validated and not structured. Tags are not (yet) used by major web search engines for the same reason the content of HTML <meta>elements are not used, there is no trusting of metadata, especially for data that is not visibly rendered in the page. This is also true of other systems using the same mechanism, such as microformats. If the search systems had more awareness of the context of tagging including the person involved, this would probably allow some more trust to be given to tags influencing web search. Of course search engines on tagging sites themselves do let you search and browse by tag, but they allow this as they have a trust model either by knowing all the context of a Tagging (Flickr, deli.cio.us) or it is their primary purpose to exist (Technorati).
Joining up tagging systems is often called a “mashup” which involves assuming that the weak identifiers that are tags are good-enough as primary keys to allow the connections to be made. The major service discussed here that does this is Technorati which joins tags in web pages, Flickr and searches into pages about tags as primary content. These joins are weaker than they could be since there are probable related information nearby that could decide whether the join should be made. The semantic web community has considered this for some time and has techniques to do this called “smushing”[BID03] potentially using multiple properties of an entity to join.
There are also a bunch of syntax-related problems such as what characters are allowed in tags (is a non-break space allowed?) or whether "foo bar" and foo bar and foobar are the same. Case is already mostly ignored, although that has it's own set of internationalisation problems. Should plurals of words be folded together? Should tags go through a stemming process? This seems a step too far from just syntax. Mejias [MEJ05]gives specific ideas on picking good tags including details of syntax choices but this has not gone beyond the proposal stage.
It was described above that specially created tags are often used for current events, and some of this is done by pre-organising the tag names. The most media-savvy events even advertise the tag during the event itself. XTech 2005 had the first (I claim) tag-based aggregator at http://planetxtech.org/ which joined on the same xtech2005 tag across: Technorati, delicious, the conference wiki and Flickr photos taken by participants. Picking the tag xtech2005 was pretty distinct and gave coherent results for the event but in general picking a name is a hard thing to do to make it short (for people) and unique (for software).
One aspect of microformats that suggests a technological way out of this, is the idea of paving the paths that are travelled. In this case, as has been discussed earlier, people will enhance a simple metadata system to meet their needs. In tagging's case, from a simple word, it gains some key:values, then multiple key:value pairs forming structures that can appear together, then richer structures that must be used together. These emerge or designed structures can be recognised and form a foundation of a semantic path out of a tag swamp.
Tagging sites do provide web APIs to manipulate tags by software as part of the open data idea that comes with these services — it is easy to get data in and out. The APIs allow exposing of what little semantics there are now in machine-readable formats such as syndication feeds which means there is somewhat of an exit for information stored in tags. There is little consistency, however in how tags are recorded in the feeds as they use different elements, formatting conventions and lose the context of the tagging operation. So this part would need aligning, although at present the number of major tagging systems is small enough that writing all the individual scraping scripts is feasible.
The major technical choice here is to separate a tag from a service that provides it, so that tags become separate entities: tagging unplugged. This does leave a gap in that tags created, are considered separate from their original sites, and some social process should then be available to come to consensus about them. This is the gap in how to find the meaning of a tag — there needs to be a place for the community of understanding to happen, for the discussion of a tag to take place and for the evolving of the discussion over time. It might be that there is consensus or not, but some record should show this and allow for the history of the change of meaning to remain so that you can ask “What did tag foo mean on date YYYY-MM-DD?” Such a community would need to be open and neutral, separate from any particular tagging site, and easy to participate in.
There is today an open way for describing and discussing concepts, with records and it's name is Wiki.
Wiki is just one way to extend the tagging process (and it does have downsides, discussed below) but it can be considered an example of a process that can build on tagging to give the kinds of semantics that people may want.
Existing tagging semantics such as geotagging or celltagging currently emerge in different places such as in a weblog, on a mailing lists or on forums around the web, although it is hard to find this since there is no standard way to go from TAG to the consensus meaning. In a web friendly way, the step from tag onwards needs to be decentralised however (and this is a downside) let us imagine that each TAG has a well known way to make a URI for it so you go to http://wikitag.example.org/TAG and by the magic of wiki, a page is created when the first person follows the link.
The wiki format provides a simple way to describe a tag — click and edit — as well as a discussion forum, since every page has both an [EDIT] as well as a [DISCUSS] button. All the changes to a page are recorded and can be tracked, updated, reverted in the case of vandalism. Wikipedia (and other Wiki communities) have various processes behind the scenes to maintain at least the community. This can be tricky and seem too bureaucratic to some since in Wikipedia's case, it is driven by the goal of making encyclopediac-type documents with a Neutral Point of View (NPoV). This might not be what would work best as a forum for describing and discussing tags, so such a wikitag service would probably have a different policies since the aim is not to build a coherent aggregate from individual pages.
There are alternative ways to track the change of semantics over time of a community with records, such as using web forums or mailing lists with archives but these have different interaction styles and a slightly larger barrier to entry in terms of registering, which remains optional on wikis mostly. Forums and mailing lists also do not have the built-in focus on building and editing a shared single thing — a web page in this case — but they could be something also attached to a shared wiki consensus for a tag.
The centralising of a single site to perform the tag-to-person mapping is a significant downside, as it is arguable that some existing tag-using site could just become the definitive one. There are probably other more distributed approaches to this, but ultimately somebody has to provide the Wiki, and services such as Wikipedia have reached some middle ground in terms of a public service and functionality.
So imagine that a wikitag system exists and the socializing behind tags now exists, how do the meanings get recorded beyond just a wiki-page of words? There are methods for performing this from wiki-space righ tnow.
Wiki pages already allow recording more than just markup and layout, but allow assigning of categories to pages, creating info boxes with key/values and many more. These could be used as straightforward ways to go from a tag's social meaning outwards to machine-readable description. This is indeed what an existing idea called Semantic Wiki[SOU05][SEM06] proposes to do (still under active development) and has some implementations which allow recording of typed links and typed attributes in pages, with mappings to RDF. However, there are other key aspects of the community description that are also recorded and relevant to describing tags; one of these is addressing ambiguity.
In wiki pages, some particular term may be used in multiple different ways and so the primary page for the term cannot be assigned to one term. When this happens, the page is split into separate pages and the main page becomes a disambiguation pagewith pointers to the new pages. This is recorded in the raw wiki text by means of {{disambig}}, so now software can tell when a term is ambiguous — and the result of this was arrived by wiki consensus. It is not always the case that the terms are split into separate pages, as sometimes there is a primary meaning and subsidiary meanings, and in those cases a different style of recording it is done, to allow finding the alternate meanings. In both cases, the wiki page records this, so applying this to tagging — there is now a way to get machine-readable indications of how a tag is used and when it is ambiguous.
As Wikipedia is organised now, there are also links to the multi-language version of terms, which is another aspect that tagging cannot deal with on it's own. A term could be found in the English and French wikitag spaces with both descriptions given a different kind of semantic relation based on translation.
One aspect wiki does not use at present and would be available when joining with tagging, is that there is the opportunity to input into the system the items that are using the tag. The page, and indeed the group behind it, could see the feed of items — pictures, blog entries etc. tagged and use this to update the community's shared understanding. This is more like a Technorati aggregated page for a tag, but with a way to edit the page itself and to discuss and track the changes.
The semantics recorded in tagging as possibly made available by a wiki-style system above can be read by software since they have emergent formalisms. This is a combination of the tag information, the tagging process, the additional community-consensus parts that are recorded in the wiki space. Pulling this together into one model is suited for a URI-based data description language with flexible schemas, which RDF provides out of the box.
The operation of tagging and the tags themselves can be modelled in RDF which has already been proposed by Newman in [NEW05].The following is one way to encode a tagging operation (given in the Turtle[BEC06] RDF syntax format):
@prefix ex: <http://example.org/> .
ex:post tags:tag <http://example.org/tagging/1> .
<http://example.org/tagging/1> a
tags:Tagging ;
tags:associatedTag tag:great , tag:interesting ;
tags:taggedBy [ foaf:mbox <mailto:r@example.com> ] ;
tags:taggedOn "2005-12-03T21:15:00Z"^^xsd:dateTime .
which records the tagging operation (URI <http://example.org/tagging/1>) using two tags ”˜tag:great' and ”˜tag:interesting' to describe a post with URI <http://example.org/post> . The tags themselves are declared like:
tag:great a tags:Tag ;
tags:tagName "great" .
tag:interesting a tags:Tag ;
tags:tagName "interesting" .
to give the mapping between the tag URI and the literal. This is mostly due to a syntax restriction of RDF that prevents literals as subjects in RDF/XML, otherwise the simple literals could be used. This approach might have additional benefits since it would allow alternate language labels for a tag URI to be added.
This encoding is just an example of how to map tags to RDF, the main benefit is that the other semantics can fit into this model as they emerge, since RDF's semi-structured nature is designed to handle this natural evolution of schemas. Although an RDF schema is not required for this to work.
The geo latitude and longitude actually already came from existing RDF work, so it already fits into this model, as the properties are the same. Similarly it would be easy to make a US zipcode property with the value of the integer zip code.
The celltagging and bluetagging structures map into RDF classes and properties straighforwardly hanging off the tagging object, something like:
<http://example.org/tagging/1>
cell:tagged [
a cell:Tagging;
cell:network “MyNetwork” ;
cell:mcc 300 ;
cell:mnc 400 ;
cell:lac 5000 ;
cell:cellid 6000
]
This snippet could even be in a different file and RDF graph merging would make it appear in the proper place in the result.
The other uses that appear when using tags in a key/value form turn into different RDF forms, since some are used to classify (assign an item to a class) and some as description. These aren't always entirely clear for example in del.icio.us the tag system:filetype:mp3could turn into typing and description:
<http://example.org/file> a
ietf:Audio-MP3-File ;
dc:format “audio/mp3” .
with possible subclassing:
ietf:Audio-MP3-File rdf:subClassOf ietf:Audio-File .
which would allow additional conclusions given some inferencer. Hierarchies inside tag names could also be turned into class-based hierarchies for the resource to be an instance-of, moving the semantics into visibility in RDF.
Modelling of annotated concepts described by implict words, organised in a hierarchy is similar to a taxonomy such as can be described by the W3C's SKOS vocabulary, although it is a simple model, it may not entirely match to an ad-hoc hierarchy built inside tag-space.
RDF can also provide other technologies such as OWL for more advanced constraints and inferencing and SPARQL for querying the RDF graphs that result which will not be discussed here.
Tagging is a social process with a gap — the social space for the community of people who build the meaning. This paper has suggested a method for using Wikis to build such a process and to record the consensus / agreements / disagreements as the meaning changes over time.
A single Wiki approach would work but it is not a good web-wide way to provide multiple answers to how to describe tags without putting too much control into one site, so further consideration on how to make this scale would need to be done such as with feed technology of callbacks/pings or some other distributed database.
Some people think that the semantic web is a top-down system, requiring big ontologies and particular XML syntaxes to function. None of this is true. The key point discussed here that it is important to focus on a clear base model for describing things on the web, allowing higher level connections and application-specific vocabularies to be layered. There is no need to re-invent a metadata schema language for syndication feed extensions, a tag query language or pretend that XML namespaces provides all you need (one of many RSS fallacies). RDF can provide answers for this today with out-of-the-box open source applications that can run them.
[BEC06] D. Beckett, Turtle Terse RDF Triple Language, 4 April 2006, http://www.dajobe.org/2004/01/turtle/
[BID03] M. Biddulph, Sha1ing, smushing and aggregating FOAF, 3 February 2003 , http://www.hackdiary.com/archives/000021.html
[BUT05] S. Butterfield, The New New Things, 1 August 2005, Flickr Blog, http://blog.flickr.com/flickrblog/2005/08/the_new_new_thi.html
[GAL05] D. Galbraith, Tagging and the Semantic Web, 11 April 2005, http://www.davidgalbraith.org/archives/000764.html
[GOL06] S. A. Golder and B.A. Huberman, Usage patterns of collaborative tagging systems, Journal of Information Science, Vol. 32, No. 2, 198-208 (2006), DOI: 10.1177/0165551506062337
[GUY06] M.Guy and E. Tonkin, Folksonomies: Tidying up Tags?, D-Lib Magazine, January 2006, Volume 12 Number 1 ISSN 1082-9873, http://www.dlib.org/dlib/january06/guy/01guy.html
[MEJ05] U. A. Mejias, Ideant: Tag Literacy, April 2005, http://ideant.typepad.com/ideant/2005/04/tag_literacy.html
[NEW05] R. Newman, Tag Ontology Design, 2005, http://www.holygoat.co.uk/projects/tags/
[NOT05] M. Nottingham and R. Sayre, The Atom Syndication Format RFC4287, December 2005, http://www.ietf.org/rfc/rfc4287.txt
[PIL04] M. Pilgrim, The myth of RSS compatibility, 4 Feb 2004, http://diveintomark.org/archives/2004/02/04/incompatible-rss
[SEM06] SemWiki2006 Workshop — From Wiki to Semantics, co-located with the 3rd Annual European Semantic Web Conference (ESWC), 11th - 14th June 2006, http://www.semwiki.org/
[SHI05] C. Shirky, Ontology is Overrated: Categories, Links, and Tags, 2005, http://shirky.com/writings/ontology_overrated.html
[SOU05] A. Souzis, Building a Semantic Wiki, IEEE Intelligent Systems, vol. 20, no. 5, pp. 87-91, September/October 2005.
[TER05] D. Terdiman, Folksonomies Tap People Power, 1 Feb 2005, http://www.wired.com/news/technology/0,1282,66456,00.html