10:19 AM
How Digg is Built
Written by Dave Beckett • Filed under Technology
At Digg we have substantially rebuilt our infrastructure over the last year in what we call "Digg V4". This blog post gives a high-level view of the systems and technologies involved and how we use them. Read on to find out the secrets of the Digg engineers!
Let us start by reviewing the public products that Digg provides to users:
- a social news site for all users,
- a personalized social news site for an individual,
- an Ads platform,
- an API service and
- blog and documentation sites.
These sites are primarily accessed by people visiting in browsers or applications. Some people have Digg user accounts and are logged in; they get the personalized site My News. Everyone gets the all user site which we call Top News. These products are all seen on 'digg.com' and the mobile site 'm.digg.com'. The API service is at 'services.digg.com'. Finally, there are the 'about.digg.com' (this one) and 'developers.digg.com' sites which together provide the company blog and documentation for users, publishers, advertisers and developers.
This post will mainly cover the high-level technology of the social news products.
What we are trying to do
We are trying to build social news sites based on user-submitted stories and advertiser-submitted ad content.
Story Submission: The stories are submitted by logged-in users with some descriptive fields: a title, a paragraph, a media type, a topic and a possible thumbnail. These fields are extracted from the source document by a variety of metadata standards (such as the Facebook open graph protocol, OEmbed plus some filtering) but the submitter has the final edit on all of these. Ads are submitted by publishers to a separate system but if Dugg enough, may become stories.
Story Lists: All stories are shown in multiple "story lists" such as Most Recent (by date, newest first), by topic of the story, by media type and if you follow the submitted user, in the personalized social news product, MyNews.
Story Actions: Users can do actions on the stories and story lists such as read them, click on them, Digg them, Bury them, make comments, vote on the comments and more. A non-logged in user can only read or click stories.
Story Promotion: Several times per hour we determine stories to move from recent story lists to the Top News story list. The algorithm (our secret sauce!) picks the stories by looking at both user actions and content classification features.
How do we do it?
Let us take a look at a high level view of how somebody visiting one of the Digg sites gets served with content and can do actions. The following picture shows the public view and the boundary to the internal services that Digg uses to provide the Pages, Images or API requests.
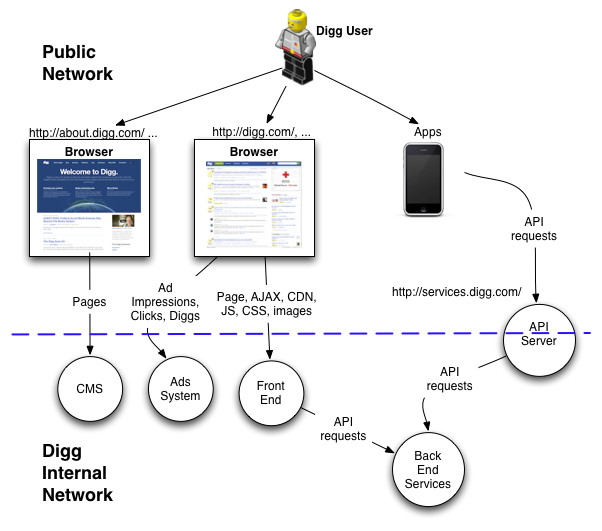
The edge of our internal systems is simplified here but does show that the API Servers proxy requests to our internal back end services servers. The front end servers are virtually stateless (apart from some caching) and rely on the same service layer. The CMS and Ads systems will not be described further in this post.
Taking a look at the internal high level services in an abstract fashion, these can be generally divided into two system parts:
- Online or Interactive or Synchronous
- Serve user requests for a page or API directly or indirectly. These have to return the response in some number of milliseconds (for services) which in aggregate to the user cannot be more than 1 or 2 seconds to give a good page response. This includes AJAX requests which are asynchronous for the user in the browser but are request/response from the serving system point of view.
- Offline or Batch or Asynchronous
- Serve requests that are not in the interactive request-response loop and are typically only indirectly initiated by a user. The work here can take from seconds, minutes or hours (rarely).
The two parts above are used in Digg as shown in this diagram:
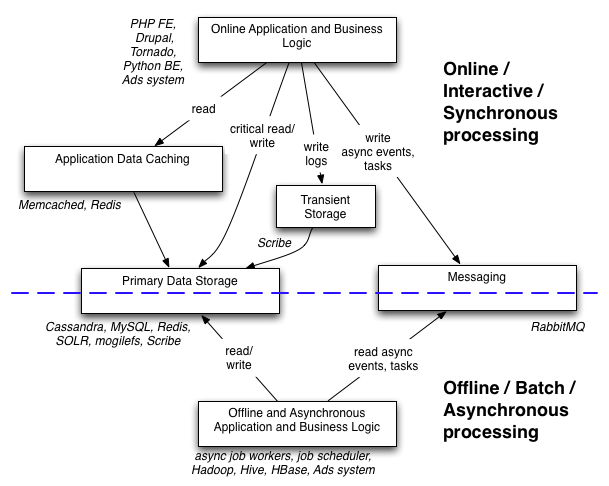
Looking deeper into the components.
Online Systems
The applications serving pages or API requests are mainly written in PHP (Front End, Drupal CMS) and Python (API server) using Tornado. They call the back end services via the Thrift protocol to a set of services written in Python. Many things are cached in the online applications (FE and BE) using Memcached and Redis; some items are primarily stored in Redis too, described below.
Messaging and Events
The online and offline worlds are connected in a synchronous fashion by calls to the primary data stores, transient / logging systems and in an asynchronous way using RabbitMQ to queue up events that have happened like "a user Dugg a story" or jobs to perform such as "please compute this thing".
Batch and Asynchronous Systems
When a message is found in a queue, a job worker is called to perform the specific action. Some messages are triggered by a time based cron-like mechanism too. The workers then typically work on some of the data in the primary stores or offline stores e.g. Logs in HDFS and then usually write the results back into one of the primary stores so that the online services can use them. Examples here are things like indexing new stories, calculating the promotion algorithm, running analytics jobs over site activity.
Data Stores
Digg stores data in multiple types of systems depending on the type of data and the access patterns, and also for historical reasons in some cases :)
Cassandra: The primary store for "Object-like" access patterns for such things as Items (stories), Users, Diggs and the indexes that surround them. Since the Cassandra 0.6 version we use does not support secondary indexes, these are computed by application logic and stored here. This allows the services to look up, for example, a user by their username or email address rather than the user ID. We use it via the Python Lazyboy wrapper.
HDFS: Logs from site and API events, user activity. Data source and destination for batch jobs run with Map-Reduce and Hive in Hadoop. Big Data and Big Compute!
MogileFS: Stores image binaries for user icons, screenshots and other static assets. This is the backend store for the CDN origin servers which are an aspect of the Front End systems and can be fronted by different CDN vendors.
MySQL: This is mainly the current store for the story promotion algorithm and calculations, because it requires lots of JOIN heavy operations which is not a natural fit for the other data stores at this time. However... HBase looks interesting.
Redis: The primary store for the personalized news data because it needs to be different for every user and quick to access and update. We use Redis to provide the Digg Streaming API and also for the real time view and click counts since it provides super low latency as a memory-based data storage system.
SOLR: Used as the search index for text queries along with some structured fields like date, topic.
Scribe: the log collecting service. Although this is a primary store, the logs are rotated out of this system regularly and summaries written to HDFS.
Operating System and Configuration
Digg runs on Debian stable based GNU/Linux servers which we configure with Clusto, Puppet and using a configuration system over Zookeeper.
More
In future blog posts we will describe in more detail some of the systems outlined here. Watch this space!
If you have feedback on this post or suggestions on what we should write about, please let us know. This post was written by Dave (@dajobe).
This could be considered a followup to the How Digg Works post from 2008 describing the earlier architecture.